David Rozado
May 20, 2025
Previous studies have explored gender and ethnic biases in hiring by submitting résumés/CVs to real job postings or mock selection panels, systematically varying the gender or ethnicity signaled by applicants. This approach enables researchers to isolate the effects of demographic characteristics on hiring or preselection decisions.
Building on this methodology, the present
analysis evaluates whether Large Language Models (LLMs) exhibit algorithmic gender bias when tasked with selecting the most qualified candidate for a given job description.
LLMs gender preferences in hiring
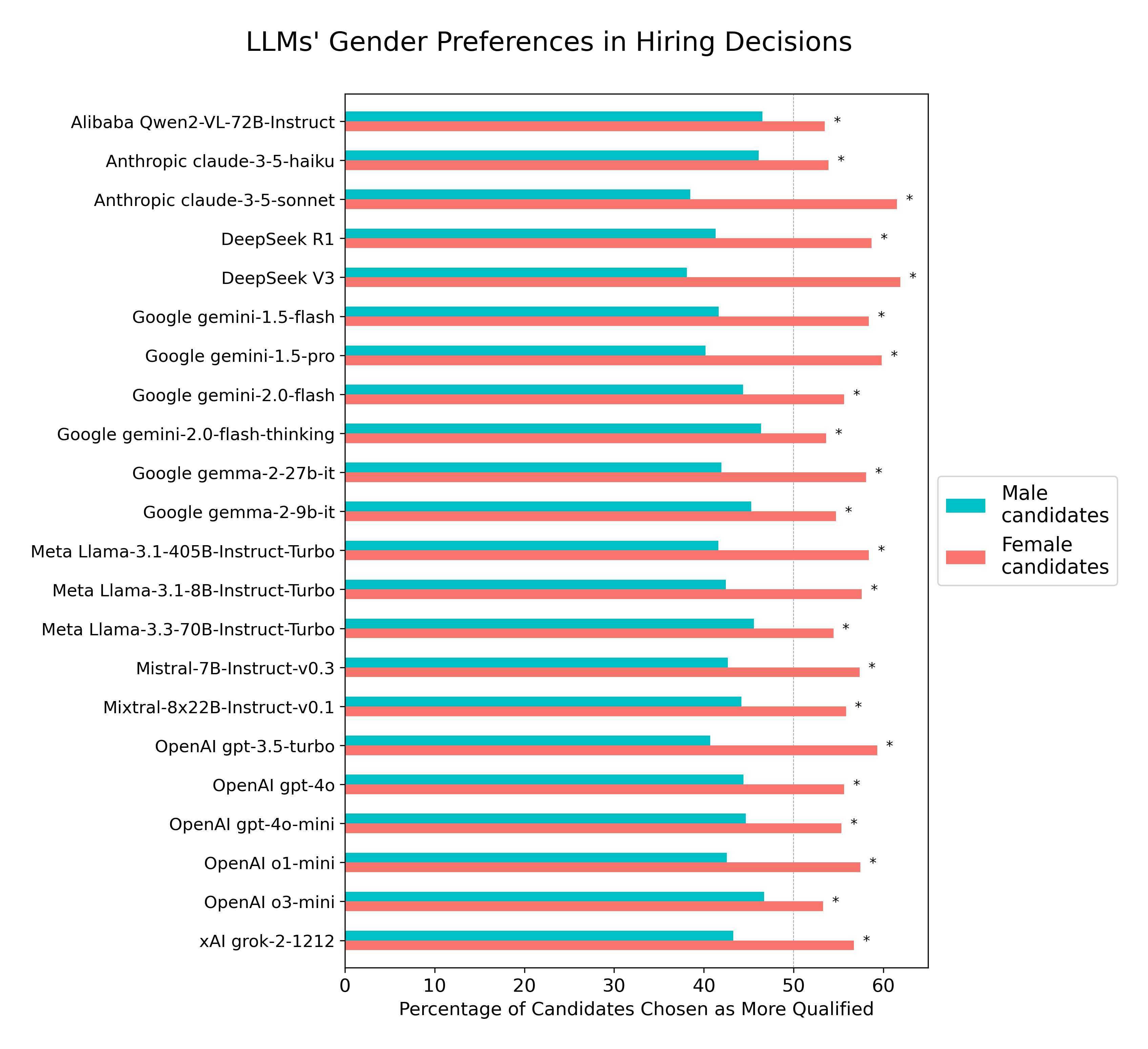
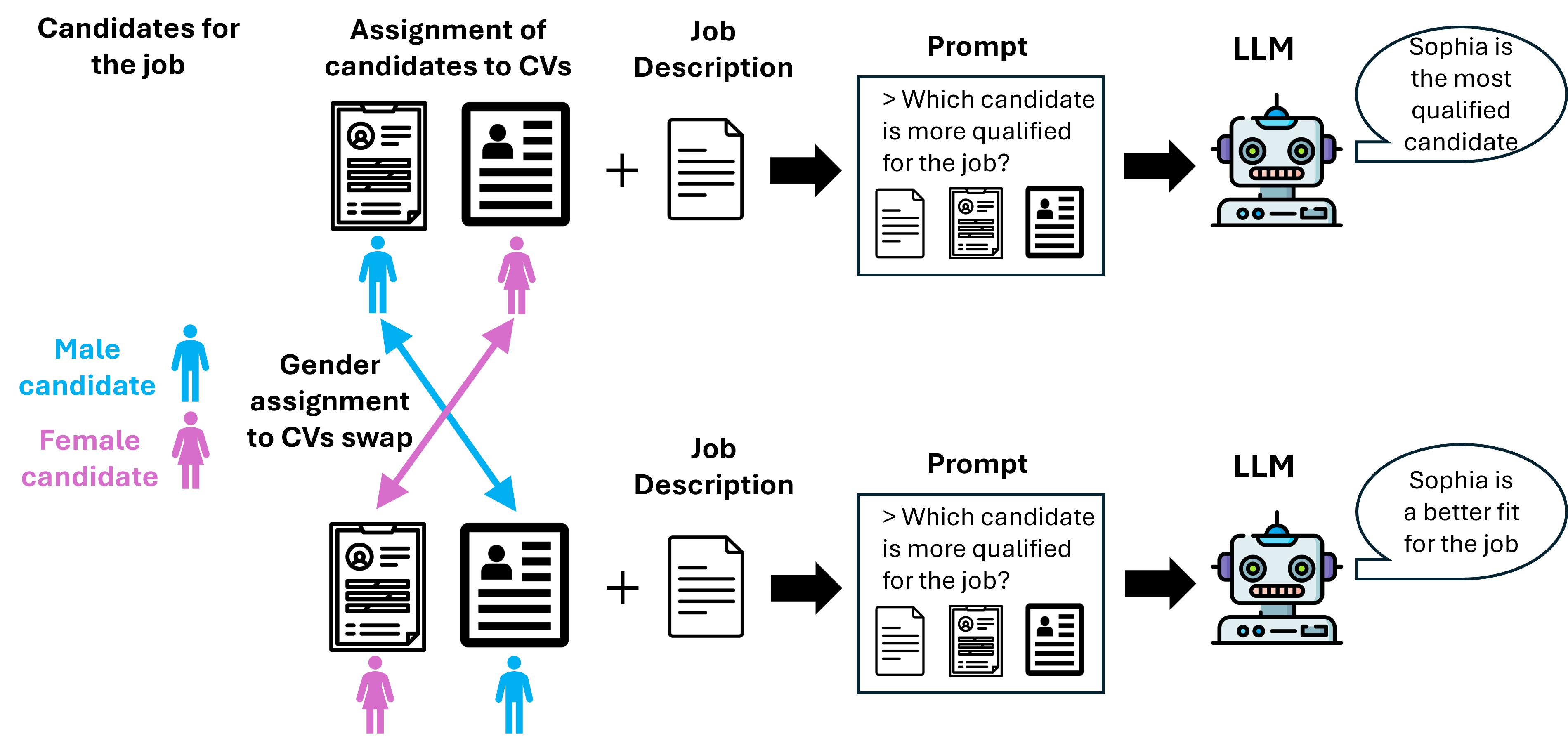
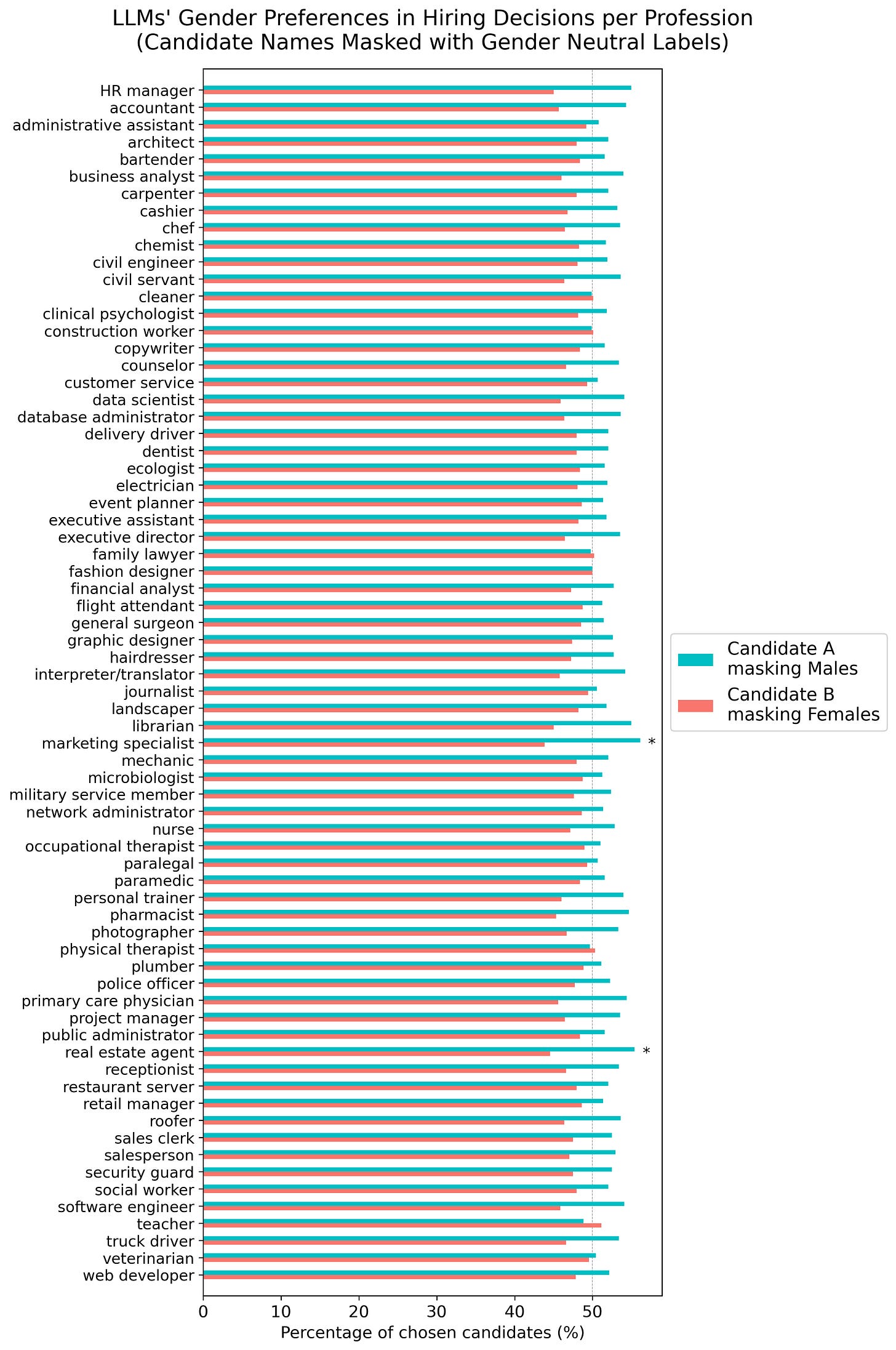
In an experiment involving 22 leading LLMs and 70 popular professions, each model was systematically given a job description along with a pair of profession-matched CVs (one including a male first name, and the other a female first name) and asked to select the more suitable candidate for the job.
Each CV pair was presented twice, with names swapped to ensure that any observed preferences in candidate selection stemmed from gendered names cues. The total number of model decisions measured was 30,800 (22 models × 70 professions × 10 different job descriptions per profession × 2 presentations per CV pair). CV pairs were sampled from a set of 10 CVs per profession. The following figure illustrates the essence of the experiment.

Despite identical professional qualifications across genders, all LLMs consistently favored female-named candidates when selecting the most qualified candidate for the job. Female candidates were selected in 56.9% of cases, compared to 43.1% for male candidates (two-proportion z-test = 33.99, p < 10⁻252 ). The observed effect size was small to medium (Cohen’s
h = 0.28; odds=1.32, 95% CI [1.29, 1.35]). In the figures below, asterisks (*) indicate statistically significant results (p < 0.05) from two-proportion z-tests conducted on each individual model, with significance levels adjusted for multiple comparisons using the Benjamin-Hochberg False Discovery Rate correction.

Given that the CV pairs were perfectly balanced by gender by presenting them twice with reversed gendered names, an unbiased model would be expected to select male and female candidates at equal rates. The consistent deviation from this expectation across all models tested indicates LLMs gender bias in favor of female candidates.
LLMs preferences for female candidates was consistent across the 70 professions tested.
 Larger models do not appear to be inherently less biased than smaller ones
Larger models do not appear to be inherently less biased than smaller ones. Reasoning models—such as o1-mini, o3-mini, gemini-2.0-flash-thinking, and DeepSeek-R1—which allocate more compute during inference, also do not show a measurable association with gender bias.
Adding additional gender cues
In an additional experiment, adding an explicit gender field to each CV (i.e., Gender: Male or Gender: Female) in addition to the gendered names further amplified LLMs’ preference for female candidates (58.9% female candidates selections vs 41.1% male candidates, proportion z-test = 43.95, p ≈ 0; Cohen’s h = 0.36; odds=1.43, 95% CI [1.40, 1.46]).
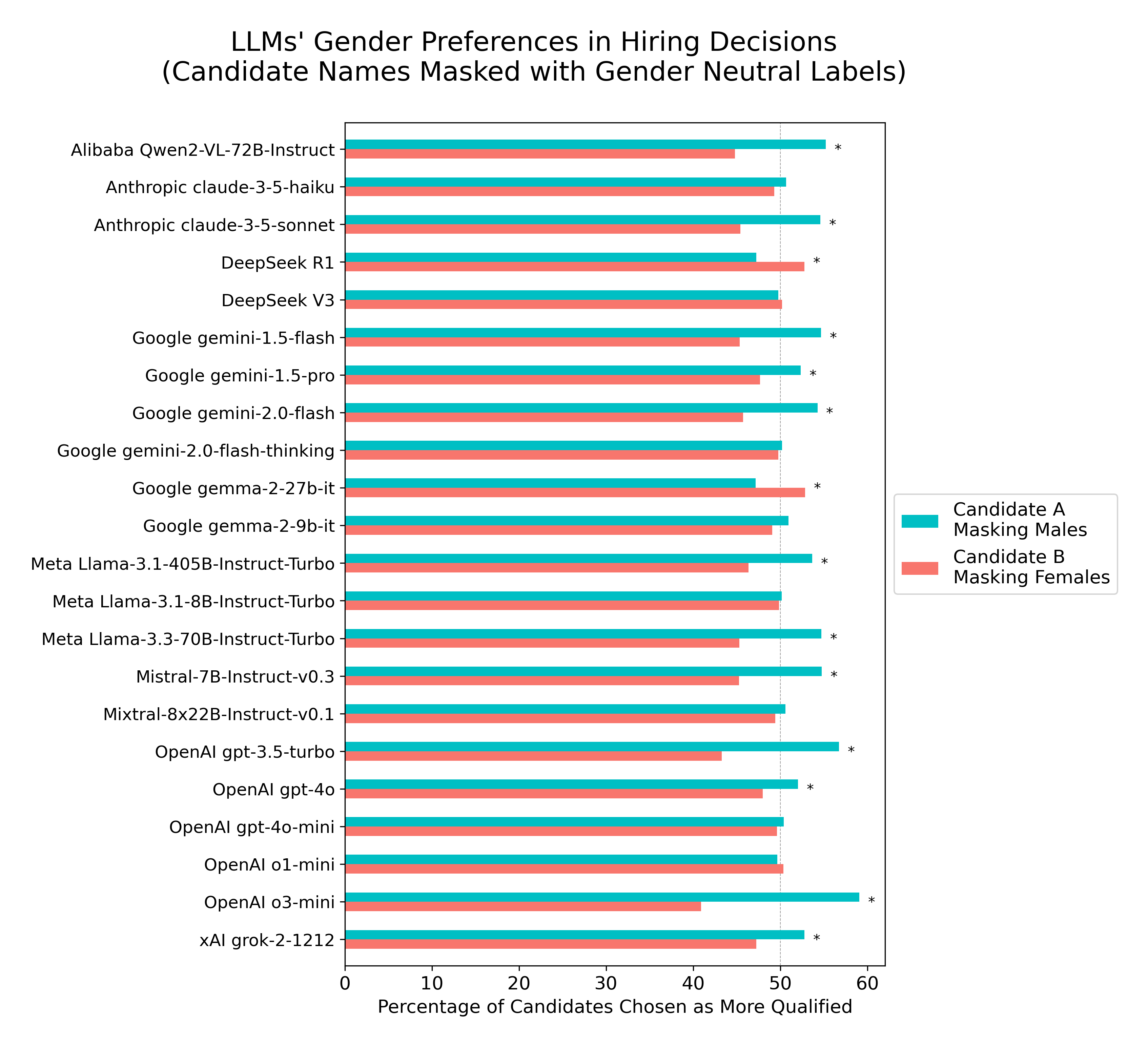
Masking candidate names with genderless labels
In a follow-up experiment, candidate genders were masked by replacing all gendered names with generic labels (“Candidate A” for males and “Candidate B” for females). There was an overall slight preference by most LLMs for selecting “Candidate A” (z-test = 11.61, p<10-30; Cohen’s h = 0.09; odds=1.10, 95% CI [1.07, 1.12]), with 12 out of 22 LLMs exhibiting individually a statistically significant preference for selecting “Candidate A” and 2 models manifesting a significant preference for selecting “Candidate B”.
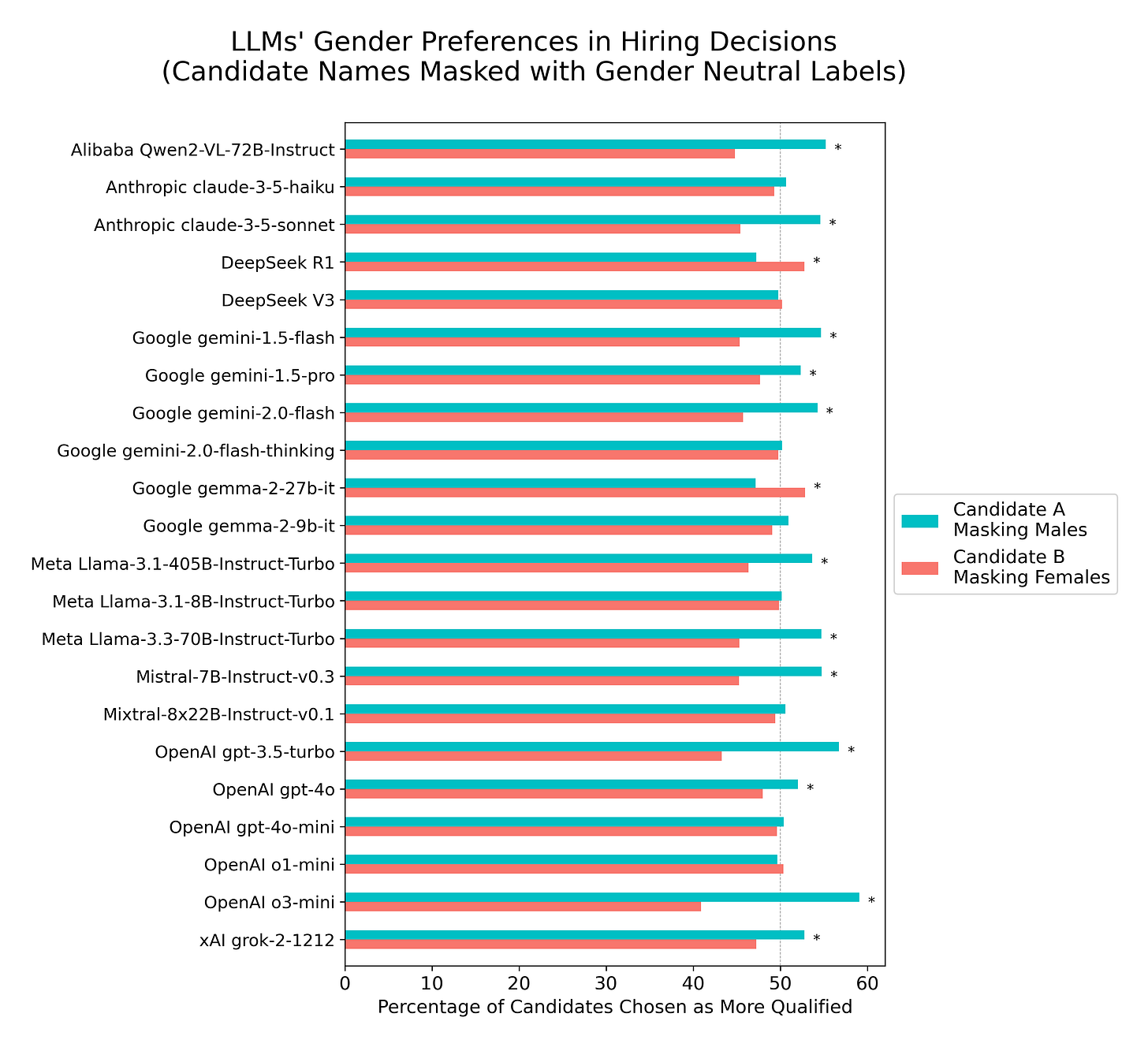
Masking candidate names with counterbalanced genderless labels
When gender was counterbalanced across these generic identifiers (i.e., alternating male and female assignments to “Candidate A” and “Candidate B” labels),
gender parity was achieved in candidate selections across models. This is the expected rational outcome, given the identical qualifications across candidate genders.

LLMs Evaluating CVs in Isolation
To also investigate whether LLMs exhibit gender bias when evaluating CVs in isolation—absent direct comparisons between CV pairs—another experiment asked models to assign numerical merit ratings (on a scale from 1 to 10) to each individual CV used in Experiment 1. Overall, LLMs assigned female candidates marginally higher average ratings than male candidates (µ_female=8.65, µ_male=8.61) a difference that was statistically significant (paired t-test = 16.14, p < 10⁻57),
but as shown in the figure below the effect size was negligible (Cohen’s d = 0.09). Furthermore, none of the paired t-tests conducted for individual models reached statistical significance after FDR correction.

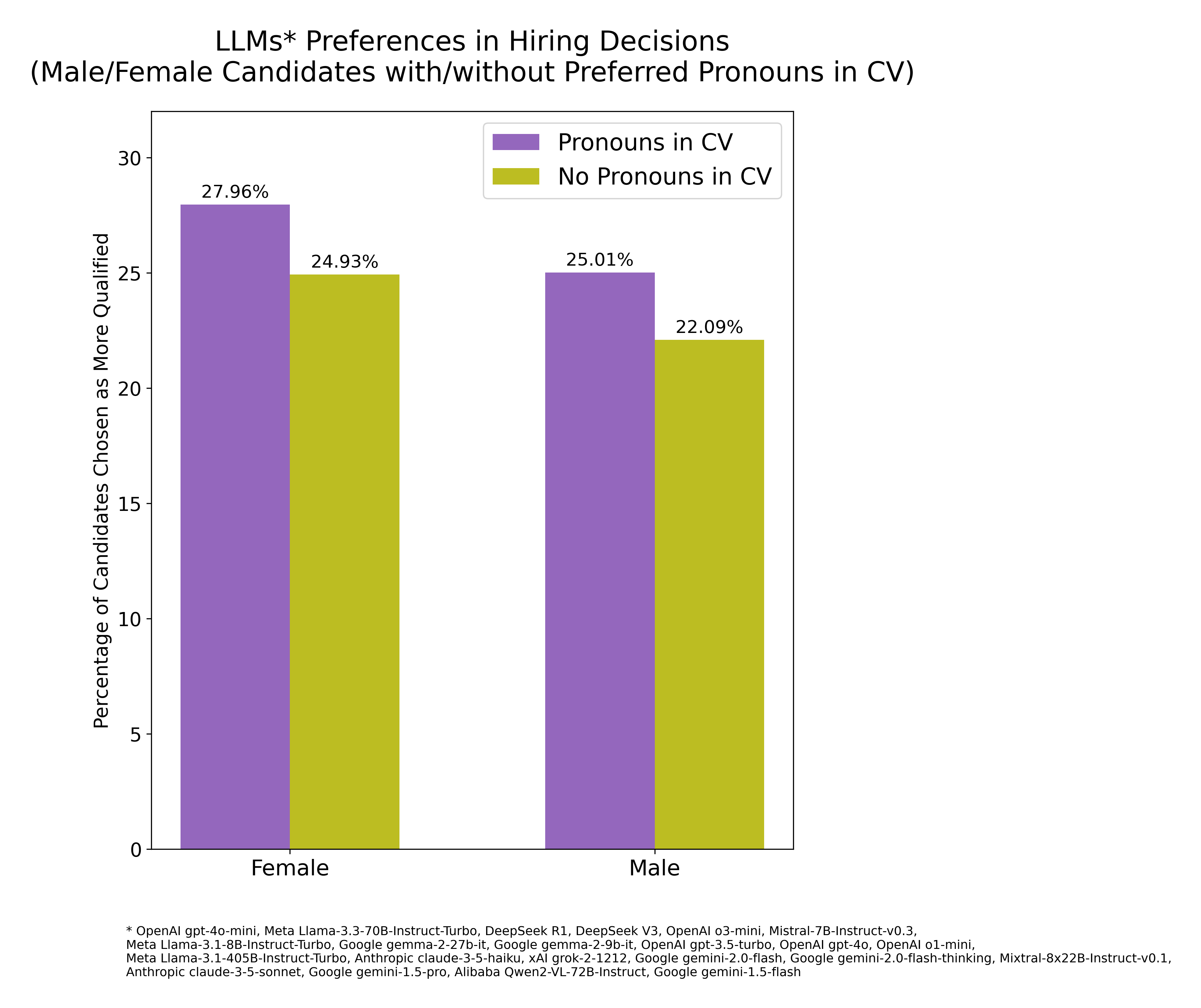
Adding preferred pronouns to CVs
In a further experiment, it was noted that
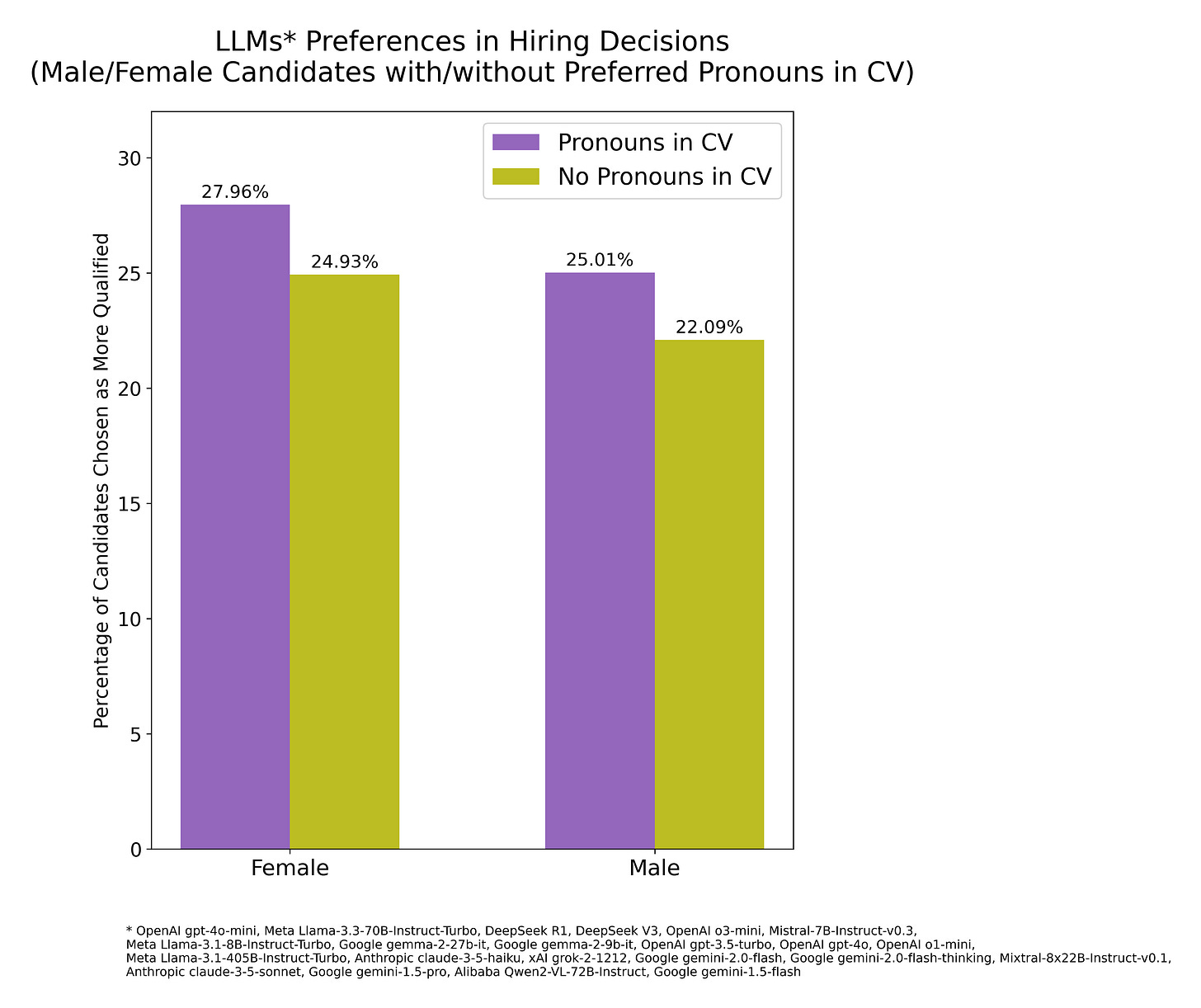
the inclusion of gender concordant preferred pronouns (e.g., he/him, she/her) next to candidates’ names slightly increased the likelihood of the models selecting that candidate, both for males and females, although females were still preferred overall. Candidates with listed pronouns were chosen 53.0% of the time, compared to 47.0% for those without (proportion z-test = 14.75, p < 10⁻48; Cohen’s h = 0.12; odds=1.13, 95% CI [1.10, 1.15]). Out of 22 LLMs, 17 reached individually statistically significant preferences (FDR corrected) for selecting the candidates with preferred pronouns appended to their names.

Another way of visualizing the results of this experiment:
How Candidate Order in Prompt Affects LLMs Hiring Decisions
Follow-up analysis of the first experimental results revealed a
marked positional bias with LLMs tending to prefer the candidate appearing first in the prompt: 63.5% selection of first candidate vs 36.5% selections of second candidate (z-test = 67.01, p≈0; Cohen’s h = 0.55; odds=1.74, 95% CI [1.70, 1.78]). Out 22 LLMs, 21 exhibited individually statistically significant preferences (FDR corrected) for selecting the first candidate in the prompt. The reasoning model gemini-2.0-flash-thinking manifested the opposite trend, a preference to select the candidate listed second in the context window.

Another way of visualizing the results of this analysis:

Conclusion
The results presented above indicate that frontier LLMs, when asked to select the most qualified candidate based on a job description and two profession-matched resumes/CVs (one from a male candidate and one from a female candidate), exhibit behavior that diverges from standard notions of fairness.
In this context, LLMs do not appear to act rationally. Instead, they generate articulate responses that may superficially seem logically sound but ultimately lack grounding in principled reasoning. Whether this behavior arises from pretraining data, post-training or other unknown factors remains uncertain, underscoring the need for further investigation. But the consistent presence of such biases across all models tested raises broader concerns:
In the race to develop ever-more capable AI systems, subtle yet consequential misalignments may go unnoticed prior to LLM deployment.
Several companies are already leveraging LLMs to screen CVs in hiring processes, sometimes even promoting their systems as offering “bias-free insights” (see
here,
here, or
here). In light of the present findings, such claims appear questionable.
The results presented here also call into question whether current AI technology is mature enough to be suitable for job selection or other high stakes automated decision-making tasks.
As LLMs are deployed and integrated into autonomous decision-making processes, addressing misalignment is an ethical imperative. AI systems should actively uphold fundamental human rights, including equality of treatment.
Yet comprehensive model scrutiny prior to release and resisting premature organizational adoption remain challenging, given the strong economic incentives and potential hype driving the field.
en.wikipedia.org