StanWildman
Orthodox
This question just came up over there and resonated with me, because I was a longtime browser who never joined and the sudden cut-off (those of us who cannot register can no longer see anything except the Announcements) came like a kick in the head. There was some great discussion there with citations and links that would have been wonderful to have saved!
I did manage, right before the cut-off, to save one single thread that proved incredibly valuable to me, which I suppose is the one thread I was meant to have ("Edifying quotes from Orthodox Saints and Elders").
Anyway, in the process, I found a workflow that saved that entire forum thread flawlessly, using the open source WinHTTrack software. I have used the software for years to save web content and mirror web sites, which has been useful for those which were destined to go dark. Although the workflow below is aimed at saving a forum thread, I recommend learning about the software if you have interest in saving more kinds of web content. StackExchange and Reddit discussions abound, and the software itself has a lively forum, so all sorts of instruction and tips are available.
Step 1 - download the software. Everyone can figure that out. Windows and Linux only I think but maybe there is Mac info somewhere. These instructions are for the Windows GUI; if you plan to use the Linux command line you definitely have the aptitude to transpose these instructions for your purposes.
Step 2 - create a folder to hold your "mirror" of the desired content. I keep all of my saved web content on dedicated storage-type drives with a lot of space to get them away from my main work areas and system files - and for easy backup. Some web sites have a lot of files to make them function, and if you go to save something with a lot of documents or media or graphics you might be talking large amounts of data.
Step 3 - run the program and click "Next"

Step 4 - Give a "New Project Name" this is just the subfolder that will be created to hold this particular mirror. For these instruction purposes I will save that RVF "Announcements" thread, just so you can see all the steps. Ignore "Product category" unless this is going to be a major part of your life in which case go ahead and use it. I organize my saved web sites by the location I keep them in so I don't need categories. Under "Base Path" click the button with 3 dots on the right and browse to the Mirrors or saved sites folder you created in Step 2 above. Then click Next.

Step 5a - Now this screen is where you set everything up. "Action" already says download web sites which is the main thing you will be doing so normally you will not touch it. When you want to "update" a mirror later on, you change this. "Web Addresses (URL)" is the first field we need to use: I am going to save the "RVF is closing" thread, so I navigate to that thread and copy its URL and paste it here.

Step 5b - but we also need to specify a few options, so click the "Set Options" button. The first thing we will set here will be the "Browser ID" tab. I do this the same way for every web site I copy and it almost always works so it is my recommendation. Change "Browser identity" to one of the Unix variant browsers. Change "HTML footer" to blank (the first option in the pull down list).

Step 5c - click on the "Scan Rules" tab (this is the only other part of Preferences I ever use). Leave all the stuff in there that is already there - it is all fine. But click at the beginning with your cursor and hit Enter 3 times to move all that stuff down so you can type 3 lines above it. On the first line type
-*
This says, first, ignore everything (insurance against accidentally trying to download all of Wikipedia or YouTube or some such externally linked content)
On the second line paste the URL again but edit it to remove the http:// leaving only the site root address, and put an asterisk at the end.
www.rooshvforum.com/threads/rvf-is-closing-on-october-29.43070/*
This gets all pages of that thread
On the third line put the site root address followed by the "styles" directory and an asterisk to pull all the style content you need to make the pages look right. (Might be a lot of files but they are small.)
www.rooshvforum.com/styles/*
Then click "Ok" to close the Preferences window, and then click "Next" to move to the next screen.

Step 6 - on this screen just click the "Finish" button and let it go to work. I don't have the image of this one because I accidentally clicked the button before screenshotting it, but it should be self-explanatory.
It will run for a little while depending on how much is on the thread, then it will move to the end screen. Don't worry about "error log" or anything else. You are now done and can close the software.
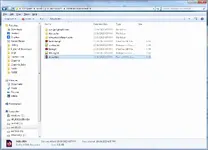
Step 7 - now use File Explore and go the folder where you saved the site, and open it. You will see a bunch of stuff that will basically look like this. Double click the "index.html" file to open it in your browser

And, voila.

If there are weird things that happen, I probably can't help much, I just found a way to make things work for me and once I do that I stick with it forever.
Helpful info was at this HTTrack forum post.
And, hello everyone, and thank you for letting me join the Forum!
I did manage, right before the cut-off, to save one single thread that proved incredibly valuable to me, which I suppose is the one thread I was meant to have ("Edifying quotes from Orthodox Saints and Elders").
Anyway, in the process, I found a workflow that saved that entire forum thread flawlessly, using the open source WinHTTrack software. I have used the software for years to save web content and mirror web sites, which has been useful for those which were destined to go dark. Although the workflow below is aimed at saving a forum thread, I recommend learning about the software if you have interest in saving more kinds of web content. StackExchange and Reddit discussions abound, and the software itself has a lively forum, so all sorts of instruction and tips are available.
Step 1 - download the software. Everyone can figure that out. Windows and Linux only I think but maybe there is Mac info somewhere. These instructions are for the Windows GUI; if you plan to use the Linux command line you definitely have the aptitude to transpose these instructions for your purposes.
Step 2 - create a folder to hold your "mirror" of the desired content. I keep all of my saved web content on dedicated storage-type drives with a lot of space to get them away from my main work areas and system files - and for easy backup. Some web sites have a lot of files to make them function, and if you go to save something with a lot of documents or media or graphics you might be talking large amounts of data.
Step 3 - run the program and click "Next"
Step 4 - Give a "New Project Name" this is just the subfolder that will be created to hold this particular mirror. For these instruction purposes I will save that RVF "Announcements" thread, just so you can see all the steps. Ignore "Product category" unless this is going to be a major part of your life in which case go ahead and use it. I organize my saved web sites by the location I keep them in so I don't need categories. Under "Base Path" click the button with 3 dots on the right and browse to the Mirrors or saved sites folder you created in Step 2 above. Then click Next.
Step 5a - Now this screen is where you set everything up. "Action" already says download web sites which is the main thing you will be doing so normally you will not touch it. When you want to "update" a mirror later on, you change this. "Web Addresses (URL)" is the first field we need to use: I am going to save the "RVF is closing" thread, so I navigate to that thread and copy its URL and paste it here.
Step 5b - but we also need to specify a few options, so click the "Set Options" button. The first thing we will set here will be the "Browser ID" tab. I do this the same way for every web site I copy and it almost always works so it is my recommendation. Change "Browser identity" to one of the Unix variant browsers. Change "HTML footer" to blank (the first option in the pull down list).
Step 5c - click on the "Scan Rules" tab (this is the only other part of Preferences I ever use). Leave all the stuff in there that is already there - it is all fine. But click at the beginning with your cursor and hit Enter 3 times to move all that stuff down so you can type 3 lines above it. On the first line type
-*
This says, first, ignore everything (insurance against accidentally trying to download all of Wikipedia or YouTube or some such externally linked content)
On the second line paste the URL again but edit it to remove the http:// leaving only the site root address, and put an asterisk at the end.
www.rooshvforum.com/threads/rvf-is-closing-on-october-29.43070/*
This gets all pages of that thread
On the third line put the site root address followed by the "styles" directory and an asterisk to pull all the style content you need to make the pages look right. (Might be a lot of files but they are small.)
www.rooshvforum.com/styles/*
Then click "Ok" to close the Preferences window, and then click "Next" to move to the next screen.
Step 6 - on this screen just click the "Finish" button and let it go to work. I don't have the image of this one because I accidentally clicked the button before screenshotting it, but it should be self-explanatory.
It will run for a little while depending on how much is on the thread, then it will move to the end screen. Don't worry about "error log" or anything else. You are now done and can close the software.
Step 7 - now use File Explore and go the folder where you saved the site, and open it. You will see a bunch of stuff that will basically look like this. Double click the "index.html" file to open it in your browser
And, voila.
If there are weird things that happen, I probably can't help much, I just found a way to make things work for me and once I do that I stick with it forever.
Helpful info was at this HTTrack forum post.
And, hello everyone, and thank you for letting me join the Forum!